
From Binary to Quaternary: 0,1,….A,T,G,C: An alternative for mainstream archival storage
DHRUV PARIKH
DR. D. Y. PATIL BIOTECHNOLOGY AND BIOINFORMATICS INSTITUTE
dhruv.kalpesh.parikh@gmail.com
INTRODUCTION
In today’s digital world, where a lot of data is being uploaded every minute, there is a need to store the relevant data safely, especially the ones that are going to be useful in the long run.
Statistically speaking, today there are 70 thousand google searches per second which go up to a mind-blowing 227 million searches an hour. About 500 hours of YouTube videos are uploaded every minute. And all this, apart from millions of social media posts that we estimated to be zettabytes (270 bytes) of data annually and increasing.
With a limited supply of silicon and the lack of enough storage, the current magnetic and optical data storage systems- that use 0s and 1s- cannot handle this data for more than a century. There is a dire need to find a solution that can not only store this digital data safely but also makes its retrieval and access cost-effective.
DNA BASED DATA STORING
DNA-based data storage can be a very useful alternative for efficient and long-term storage of archival data, say potentially important government records.
The material that transfers the genetic information from one generation to the next can be leveraged to store the zettabytes of data generated annually.
The density and the durability of the DNA are several folds greater than the existing silicon-based data storage devices. DNA’s four-letter universal code can be used to store the data more efficiently as compared to the binary code.
After years spent on DNA-based data storage and trying to reduce its cost, scientists have developed enzyme-based approaches that, unlike the conventionally used chemical techniques, can write DNA in simpler and faster ways, apart from being less toxic to the environment.
THE METHOD
Having discussed the scope and overall gist of what DNA-based data storage could achieve, an insight into the actual process becomes necessary.
The overall process is divided into 4 phases:
- Encoding: A computer algorithm maps the digital information(in strings of bits) into a DNA sequence. These DNA sequences are synthesized using an array-based method or the synthesis of such huge amounts of DNA can be achieved by the novel Enzymatic synthesis method which uses template-independent DNA-polymerizing enzymes, such as terminal deoxynucleotidyl transferases (TdTs) to incorporate bases in a controllable fashion without a template, enabling parallel, high-throughput synthesis of large amounts of DNA. Later, since the information is very large, these sequences are fragmented with an index-unique PCR primer- assigned to each fragment which could be later used for reassembly. One great advantage of novel enzymatic synthesis is the fact that, unlike conventional techniques, this method is potentially error-free, fast, safe, and generates longer strands enabling higher storage and lower storage costs
- Storage: After the synthesis of the required amount of DNA, it needs to be cloned to be stored either in a biological cell (in vivo) or more commonly in vitro, like being frozen or being dried to protect it from the environment.
- Data Retrieval: Upon being asked for a particular data by the user, it needs to be retrieved from the DNA pool. This can be achieved by nanopore sequencing technology that mimics naturally occurring cellular membrane which acts as a passage for molecules for their to and fro movements. The motor protein located at the end of the adapter sits atop the nanopore and functions to ratchet the single-stranded DNA strands through the nanopore, embedded in an electrical membrane. As the strands pass through the nanopore, each nucleotide is detected using the characteristic fluctuation in the electric current that it brings. This enables the real-time readout of the data to the user, which is a primary requirement for rapid data retrieval. To make sure that only the requested information is being retrieved, a PCR-based random access system is used which uniquely identifies the data within the DNA pool using unique indices or primers used while encoding.
- Read: As the required piece of information is found from the DNA pool, it is then decoded back using the reads from the DNA sequencers, which fetch the specific reads from the data pool.
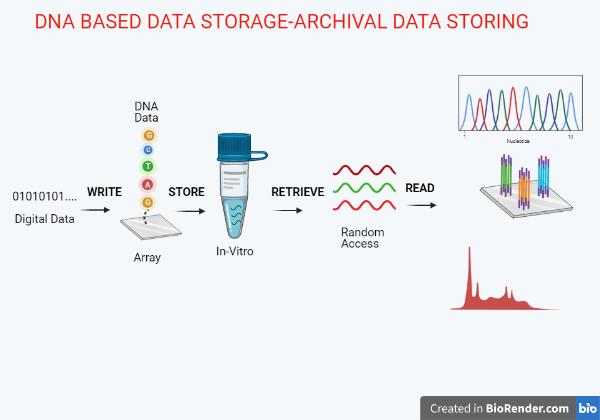
Figure 2: The Process- DNA Based Data Storage. Created with BioRender.com.
APPLICABILITY
- More Data can be stored: DNA being denser compared to the conventional storage media, can store data orders up to 1015 – 1019 bytes per mm3. These figures are several folds greater than the figures for the densest storage media available today.
- Time tested: With the advancements in technology coming up day by day, it is observed that the technologies to store and retrieve the data keep on changing very often. This brings a problem of switching from one technology to the other every time there is a change, which consumes a lot of energy and resources. DNA-based data storage offers to retain the data for very long periods, evident from the fact that DNA is recovered from million years old fossils now and then.
- Potentially Cost-Effective: With the advent of Next Generation High-throughput Sequencing technologies, the cost of sequencing the DNA is going to reduce exponentially day by day, which makes DNA an eternally relevant source for archival information storage and retrieval.
- Less Footprint and energy costs: The archival storage can bear greater associated timelines to transfer the digital data which makes it perfect to store in the most stable genetic material for information storage thus providing lesser footprints and reduced energy costs.
CHALLENGES AND SHORTCOMINGS
- Higher Latencies: Talking about time, to read the sequence while conversion to digital form, it is still high compared to its mainstream counterpart. But since it is going to be currently used for archival storage, these high latencies can be born as it is one-time.
- Physical storage and preservation of the DNA: Although DNA has been time tested, yet it can be degraded in many ways depending upon the conditions in which it is being stored. Many methods of storing DNA have been suggested by scientists, like lyophilization, or chemical encapsulation to increase the shelf-life.
- Huge-Costs: The costs for sequencing and reading are many folds higher compared to when the data is being stored through mainstream systems. These costs can be largely reduced once the DNA-based storage system is used for bulk storage.
As we move into a digital era, all the archival data that is generated needs a long-term, safe, and easily accessible system which potentially reduces the transfer costs (cost for transferring data every time the technology gets updated), makes data retrieval easy and fast. The DNA Based data storage offers all these promises.
Reference (A6-May-2021)
Author Biography: I am an undergraduate student at Dr. D.Y. Patil Biotechnology and Bioinformatics Institute, Pune pursuing B.Tech(Biotechnology). Being inquisitive for biology, having an aim to pursue my career in the field of Molecular biology, I have developed an interest in the subject of recombinant DNA technology and all its allied fields. I have a demonstrated history in scientific review writing and am always looking forward to all the latest developments in my field. I visit the webpage of BioTalk Magazine quite often to take all the updates and advancements in the research field of my interest. I find the ‘Long Reads’ section of the magazine very helpful. The articles on your web pages signify all that an undergraduate research enthusiast is looking forward to reading and so through your columns, I aspire to highlight my work as well.
